- 研究紹介インタビュー
マルチコンディション学習で多言語対応の合成音声評価が可能になるメカニズムを解明[GCCE 2022]

マルチコンディション学習で多言語対応の合成音声評価が可能になるメカニズムを解明[GCCE 2022]
2022年10月に開催されたGlobal Conference on Consumer Electronics(GCCE)2022で、 デンソーアイティラボラトリーの太刀岡勇気による論文 Multi-condition Training and System Combination for Automatic MOS Prediction がExcellent Paper Award Gold Prize(最優秀論文賞)を受賞しました。 GCCEはIEEE Consumer Electronics Societyが主催する、情報家電に関する国際会議で、 毎年10月に日本で開催されています。
本論文は、音声合成品質を自動評価するモデルの精度を競う「VoiceMOS Challenge 2022」に参加して得た知見を考察し、複数言語の合成音声を評価するモデルのメカニズムを解明したものです。論文を執筆した太刀岡さんに、VoiceMOS Challengeの成果と今回の論文で得られた知見について伺いました。

■課題:英語に比べてサンプル数の少ない他言語の合成音声の自動評価モデルの精度を上げる
−VoiceMOS Challengeというのはどのようなチャレンジなのでしょうか。
太刀岡:音声サービスの評価は、「聞く人がどう感じるか」という主観をベースに行われます。評価者に「非常に良い」から「非常に悪い」の 5段階で評価させるのですが、当然人によって評価が異なりますよね。このバラツキをなくすために、複数の評価者による評価を平均した 「MOS(Mean Opinion Score)」という定量的なスコアを用います。MOSの測定のためには、複数の測定者が条件の整った環境で、評価したい音声と 同じだけの時間をかけて聞く必要があります。手法としては確立されており信頼性が高いですが、コストと時間がかかり、大量の音声データを評価するには 適していません。
一方で、Text to SpeechやVoice Changerなどの音声合成システムの品質を上げていくためには、生成した合成音声を評価しチューニングを繰り返す必要が あります。大量の音声を高速に評価するために、入力した音声のMOSを予測する「MOS自動予測モデル」が研究されています。VoiceMOS Challengeというのは、 Interspeechという学会のスペシャルセッションとして2022年から3回開催されています。人間によるMOS評価済みの合成音声データをMOS自動予測モデルで 評価して、その精度を競います。
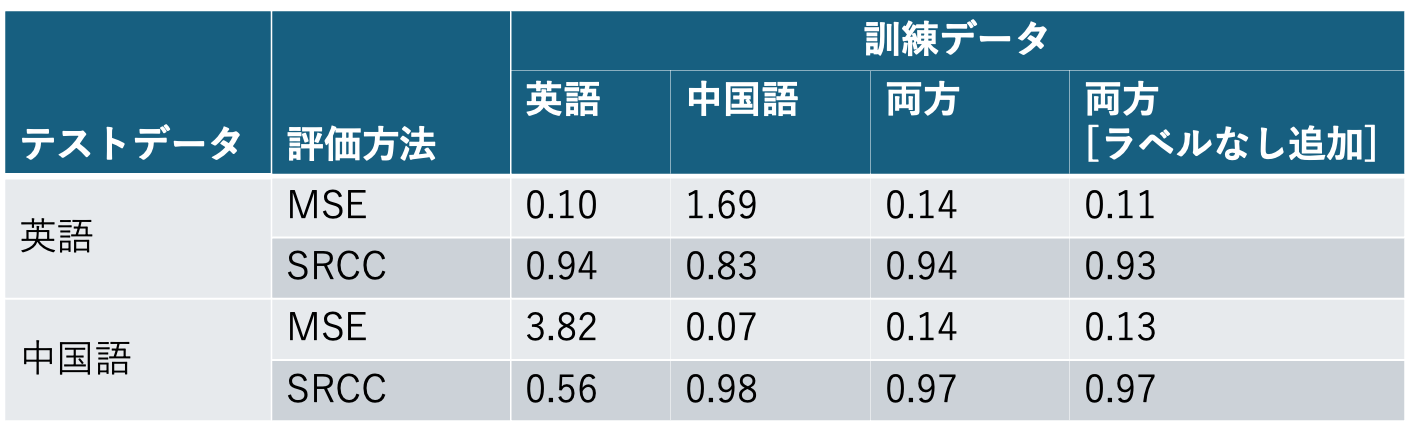
VoiceMOS challenge 2022でのテーマの一つが、「英語以外の合成音声のMOS自動予測精度」で、そのために英語のデータと中国語の合成音声データが 提供されています。英語のデータは量が多く、なおかつ、人間によるMOS評価のラベルが付いたデータも多いのですが、中国語のデータはそもそも量が少なくて、 なおかつMOS評価のラベルが付いているデータはそのうちの2割ぐらいしかありません。

-なんだか不公平に感じますね
太刀岡:英語についてはこれまでにさまざまな研究で蓄積されたラベル付きの合成音声データが豊富にあります。 対して、英語以外の言語の合成音声データの量は少ないですし、しかもMOS評価をするのは大変なので評価済みのデータはさらに少ないという、 不公平に感じるかもしれませんが、現実にありがちな状況に合わせた設定になっています。このような条件下で、中国語合成音声のMOS自動予測の精度を 上げるために、学習させるデータを変えて比較を行いました。

■英語の学習データに中国語のデータを少し加えると、両方の評価精度が高くなる
-使用したモデルはどのようなモデルですか?
太刀岡: Wav2vec2.0という自己教師付き学習(SSL)音声認識フレームワークを利用したSSL-MOSという予測システムを使用しました。 Wav2vec2.0は、事前学習済みの畳み込みニューラルネットワーク(CNN)を利用して音声波形を高次元のベクトルに変換(エンコード)します。 音声認識システムはその後段にエンコーディングしたデータから単語や文章を抽出する文脈認識用のネットワークを置くことで、波形から音声を文字に変換しますが、 SSL-MOSは、代わりにMOS予測のためのネットワーク(MOS予測器)を接続します。システム全体をVoiceMOS Challengeで提供されたデータで再学習することで、 合成音声からMOSスコアを予測できるようになります。
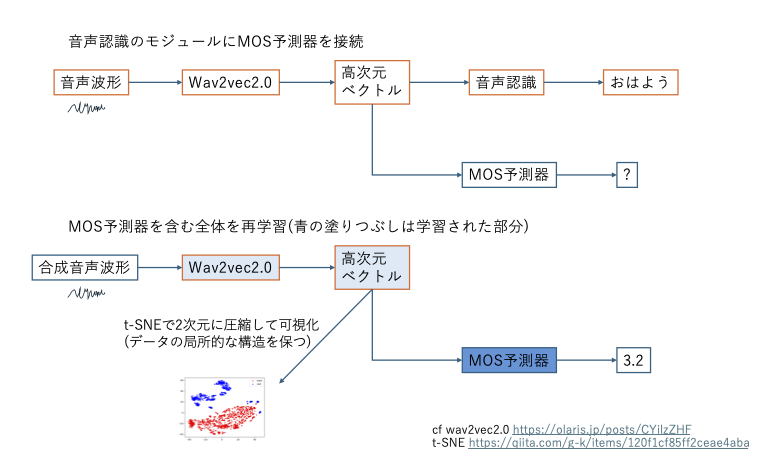
-どのような事前仮説があったのでしょうか。
太刀岡: まず、英語のデータと中国語のデータを一緒に学習させると、評価予測の精度は上がるのではないかと考えました。 というのは、音声認識の場合、クリーンなノイズ無しのデータだけで学習すると、少しでもノイズが入ると認識精度が著しく落ちてしまいます。 これを防ぐために、何種類かのノイズが入ったデータを混ぜて学習させる「マルチコンディション学習」によって、さまざまなコンディションでの 認識精度を上げるという手法があります。合成音声の評価についても、同様に、英語と中国語のデータを一緒に学習させるマルチコンディション学習に することで、MOS評価予測の精度も上がるのではないかと予想しました。

実験で確認したのは以下の4点です。精度の評価は、主に音声の評価の「順位」が、人が評価したMOSの順位と合致しているかどうか、 つまり人間が高く評価したデータを高評価に、低く評価したデータを低評価に予測できているかを基準としました。
-結果はどうだったのですか。
太刀岡:どちらか片方のデータだけを学習に使用した1.,2.については、当然ですが、学習に使用した言語の音声のMOS評価予測に比べて、 異なる言語の音声のMOS評価予測は著しく精度が低くなりました。
対して、3.については、それぞれの言語で学習したモデルとほぼ近い精度のMOS評価予測ができました。つまり、マルチコンディション学習したモデルは、 英語音声の評価も中国語音声の評価も両方予測できることになります。4.のラベル無しデータを学習に使用したモデルは、スコアの絶対値の誤差は若干減りましたが、 順位を基準にした場合の精度は使用しない場合と変わりがありませんでした。
最初に述べた通り、VoiceMOS Challenge 2022で提供されたトレーニング用のデータの量は英語に比べて中国語は非常に少ないです。 データの量がアンバランスでも一緒に学習させることで、両方の言語のMOS評価予測ができることが示せました。音声合成システムの多言語対応を進めていく上で、 多言語対応のMOS評価予測モデルを作りやすくなることが示せたわけです。
■音声波形から最初に英語と中国語が識別されていたことを発見
太刀岡:ここまでは2022年のInterspeechのVoiceMOS Challengeで得られた知見ですが、 なぜマルチコンディション学習のモデルで両方が精度高く評価できるのかをもう少し深掘りしてみたのがGCCE2022の発表です。 1.,2.,3で用いた学習済みモデルのWav2vec2.0が出力する高次元ベクトルをそれぞれのデータで分析しました。 実際には768次元のベクトルなのですが、これをt-SNEという手法で2次元に変換し、散布図を描いてみました。
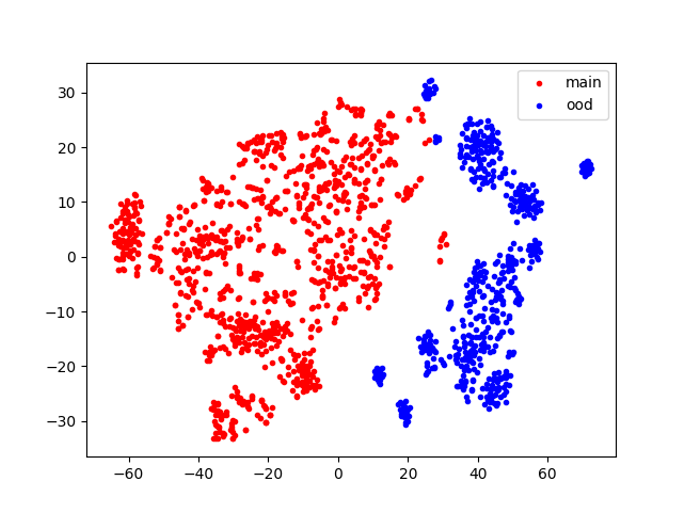
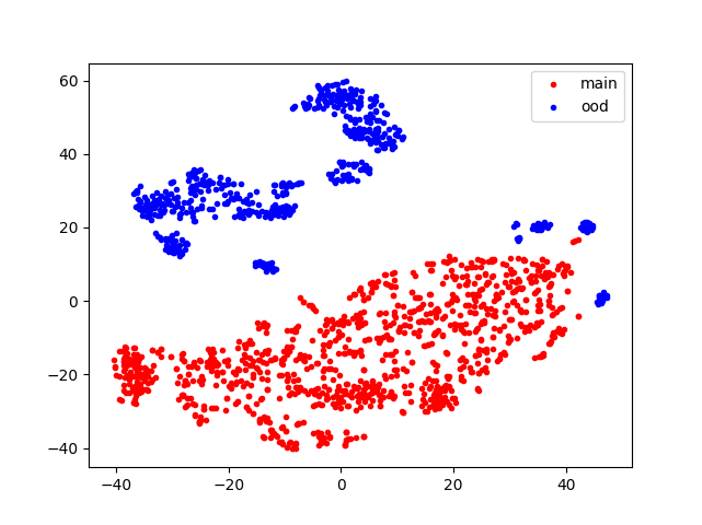
左の図の赤い点は、1.で用いた英語のみを学習したモデルで英語のテストデータから出力したベクトル、青い点は2.で用いた中国語のみを学習したモデルで中国語のテストデータから出力した ベクトルです。右の図は3.で用いた「英語と中国語を混ぜて」学習したモデルが出力したベクトルで、赤い点は英語のテストデータ、青い点は中国語のテストデータを 表しています。
別々に学習したモデルよりも、混ぜて学習したモデルの方が、平面上で赤い点と青い点の距離が離れていることがわかります。 これは、英語音声と中国語音声の両方でトレーニングしたモデルの方が、MOS予測器に入る前の段階で音声波形から英語と中国語をより正確に識別できていることを 示唆しています。

-私たちは音を聞くだけで意味がわからなくても「英語らしい」「中国語らしい」と感じますが、同じようなことがこのモデルでも起きているということですか?
太刀岡:その通りです。英語のラベル付きデータに少しだけ中国語のラベル付きデータを足して再学習することで、中国語の特徴をうまく抽出できるようになり 言語を識別できるようになっています。英語音声と中国語音声では音韻やアクセントの特徴が異なりますので、聞きやすさやわかりやすさを評価する時のポイントが 違ってきます。なので、最初に言語を識別してから言語ごとのポイントを踏まえて評価することで、MOS評価予測の精度も上がっているのだと考えられます。
-別の言語のデータは少しだけ加えればいいとのことですが、どのくらい少なくてもいいんですか?
太刀岡:今回トレーニングに使ったラベル付きデータは、英語が約5000サンプルに対して中国語が約100サンプルでした。つまり今回の結果は、 新しい言語の学習用データの割合が2%程度であっても、2つの言語を識別することが可能であることを示しています。
ラベル付き音声データを作成するのはとにかく時間がかかります。例えば、100サンプルのラベル付きデータを用意するために、 1サンプルあたり10秒だったとすると、約1,000秒分の音声を聞き、評価する必要があります。すると最低でも30分程度はかかりますよね。 MOSを算出するためには最低でも4人程度の評価者の点数を平均しますので、のべ2時間程度の評価が必要になります。英語と同じ量、5000サンプルの ラベル付きデータを作成するには100時間の評価が必要になりますが、それが2時間で済むことになりますので、新しい言語に対応するモデルを作るための ラベル付き音声データの作成にかかる時間を大幅に短縮できます。
■今後の可能性:人が「良い」と評価する品質に最適化した音声合成システムの開発へ
-音声合成システムの多言語対応を進める上で、品質評価を自動化しやすくなるのは大きなインパクトがありますね。 今後この研究成果はどのように応用されていくのでしょうか。
太刀岡:音声合成システムの評価を機械的に行う場合、現在はリファレンス音声との比較をベースにしています。 学習データの収録した人間の音声波形と合成音声の波形の差が小さいほど良いという評価をします。 でも実際は、波形が近いからといってMOS評価の高い、すなわち人が聞きやすいと感じる、品質のいい音声だというわけではないんですね。 本来であれば、波形が違っても品質の良いものを「良い」と評価したいのですが、そのためには人が時間をかけて評価するしかありませんでした。
MOS予測システムの精度が上がれば、時間とコストをかけずに音声合成システムの品質を評価できるようになります(応用例1)。 少しずつパラメーターを変えたりして、たくさんの音声合成システムを作っても、MOS自動評価ができれば今に比べて最適な音声合成システムを選択できます (応用例2)。
もう一つの応用が音声合成システムのトレーニング時にMOSを最適化するように学習させることです(応用例3)。 出力された合成音声を人間が聞く代わりに、出力された合成音声の波形をMOS予測システムに入力して、出力されたスコアを使ってチューニングします。 人間が音声を評価するのは時間がかかりますし、大量のデータを評価すると最初と最後で評価にブレが出ることがありますが、MOS予測システムはそれがありません。 なおかつ、MOSを最適化する、すなわち人が聞いて品質が高いと評価するようにシステムを学習させることができるようになります。
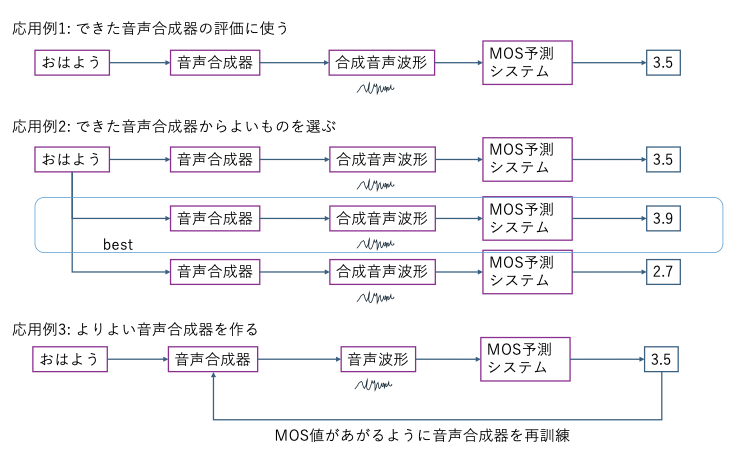
-実際に論文などで音声合成システムの評価をするのにMOS自動予測システムを使っている例はあるのですか?
太刀岡:研究は進んでいるのですが、実際に評価に使われるには、研究者の中で「MOS自動予測システムの出力は精度が高く、 人間のMOS評価の代わりに使えると信頼してもいい」というコンセンサスが成立する必要があります。 今はまだそこまではいっていないので、論文を執筆する時にも、人に聞いて評価してもらう必要があります。
-太刀岡さんご自身は、今後音声合成の分野でどのような研究をしていきたいと考えていらっしゃいますか。

太刀岡:元々は音声認識や音声信号処理を研究していたのですが、徐々に研究テーマがシフトして、今は「感情豊かな音声合成」をテーマにしています。 例えば、平板な音声ではなく、楽しそうな声で人間と会話ができるアプリを研究しています。自動運転のではドライバーが眠くなってしまうので、 居眠り防止のための機能としてそのうちカーナビに組み込まれるかもしれません。
-確かに、声は文字よりもダイレクトに感情に届くので、いろいろな場面で合成音声が受け入れられるためには「感情」って大事かもしれませんね。 カスタマーサポートにクレームの電話をかけた時に、いかにも機械っていう合成音声で応答されると怒りが増しそうですが、申し訳なさそうな声に聞こえると 少し気持ちが収まりそうです。
太刀岡:合成音声が生活の中に浸透するほど、正確に情報を受け取ってもらうために、流暢であることや、感情が乗ることが重要になってくると思います。 そのためにも、「人間に好ましい音声」を音声合成で作りたいと思っていますし、今回の研究成果も役立てていけると考えています。
-ありがとうございました。







